[DataBase] 조인
1. 조인 (Join)
조인이란 하나의 테이블이 아닌 두 개 이상의 테이블을 묶어서
하나의 결과물을 만드는 것을 말한다
MySQL 에서는 JOIN 이라는 쿼리로
MongoDB 에서는 lookup이라는 쿼리로
참고로 MongoDB에서 lookup을 되도록 쓰지 말아야 한다
RDB보다 성능이 떨어진다고 하기 때문이다
조인하는 작업이 많다면 RDB를 쓰는것이 좋다
2. 조인의 종류

내부 조인 (inner join)
왼쪽 테이블과 오른쪽 테이블의 두 행이 모두 일치하는 행이 있는 부분만 표기 한다
SELECT * FROM table1 A
INNER JOIN table2 B
ON A.key = B.key
왼쪽 조인 (left outer join)
왼쪽 테이블의 모든 행이 결과 테이블에 표기 된다
SELECT * FROM Table1 A
LEFT JOIN Table2 B
ON A.key = B.key
오른쪽 조인 (right outer join)
오른쪽 테이블의 모든 행이 결과 테이블에 표기 된다
SELECT * FROM Table1 A
RIGHT JOIN Table2 B
ON A.key = B.key
합집합 조인 (full outer join)
두 개의 테이블을 기반으로 조인 조건에 만족하지 않는 행까지 모두 표기 한다
SELECT * FROM Table1 A
FULL OUTER JOIN Table2 B
ON A.key = B.key
3. 조인의 원리
1) 중첩 루프 조인 (Nested Loops Join)
2개 이상의 테이블에서 하나의 집합을 기준으로 순차적으로 상대방 Row를 결합하여
원하는 결과를 조합하는 조인 방식이다
조인해야 할 데이터가 많지 않은 경우에 유용하게 사용됩니다
NESTED LOOP JOIN은 Driving Table로 한 테이블을 선정하고
이 테이블로부터 where절에 정의된 검색 조건을 만족하는 데이터들을 걸러낸 후
이 값을 가지고 조인 대상 테이블 (Driven Table)을 반복적으로 검색하면서
조인 조건을 만족하는 최종 결과값을 얻어낸다
이는 마치 이중 for문과 같은 원리이다
for(i=0; i<dept.length; i++) { -- driving table
for(j=0; j<emp.length; j++) { -- driven table
// Search
}
}
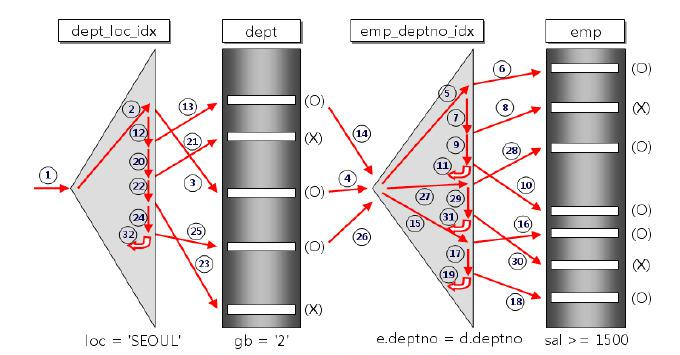
위의 그림에서 먼저 액세스 된 dept Table이 Driving Table이고
나중에 액세스 된 emp Table이 Driven Table이다
위의 그림에서 볼 수 있듯이 dept의 데이터를 추출하기 위해
dept_loc_idx라는 인덱스를 사용하여 gb = '2'인 데이터를 추출하였으며
이렇게 검색된 데이터를 가지고 같은 deptno를 가지는 사원들의 정보를
emp_deptno_idx라는 인덱스를 사용하여 sal >=1500 조건으로 emp Table을 조회하였다
Driving Table 과 Driven Table
Driving Table이란 JOIN을 할 때 먼저 액세스 되어
ACCESS PATH를 주도하는 테이블을 Driving Table이라고 한다
즉, 조인을 할때 먼저 액세스 되는 테이블을 Driving Table이라고 하며
나중에 액세스 되는 테이블을 Driven Table이라고 한다
여기서 Driving Table은 옵티마이저가 결정하고
자연스레 Driving Table이 아닌 테이블은 Driven Table로 결정된다
예시로 보자면
학생 테이블과 학교 테이블이 있을때
이름이 홍길동인 학생의 학교 정보를 알고 싶다면
학생 테이블이 Driving Table
서울대학교의 학생들의 정보를 보고자 하면
학교 테이블이 Driving Table
2) 정렬 병합 조인 (SORT MERGE JOIN)
조회의 범위가 많을 때 주로 사용하는 조인 방법론이며 양쪽 테이블을 각각 Access 하여
그 결과를 정렬하고 그 정렬한 결과를 차례로 Scan 해 나가면서
연결고리의 조건으로 Merge를 하는 방식이다
주로 조인 조건 칼럼에 인덱스가 없거나, 출력해야 할 결과 값이 많을 때 사용된다
조회의 범위가 좁을 때 유리한 Nested Loop Join의 조인 방식과 장단점이 서로 바뀌어있다고 생각하면 된다
동작 방식은 아래와 같다
select /**USER_MERGE(A B) */ A.Color, B.SIZE,...
from TABLE_A A,TABLE_B B
where a.joinkey_a = b.joinkey_b -- join key에 대한 인덱스가 테이블 둘 모두 다 없음
and a.color = 'RED' --인덱스 있음
and b.size = 'MED'; --인덱스 없음

첫 번째로 각 테이블에 대해 동시에 독릭접으로 데이터를 먼저 읽어 들인다
두 번째로 읽혀진 각 테이블의 데이터를 조인을 위한 연결고리에대하여 정렬을 수행한다
세 번째로 정렬이 모두 끝난 후에 조인 작업이 수행된다
3) 해시 조인 (HASH JOIN)
해시 조인은 조인될 두 테이블 중 하나를 해시 테이블로 선정하여
조인될 테이블의 조인 키 값을 해시 알고리즘으로 비교하여 매치되는 결과값을 얻는 방식이다
해시 조인은 비용 기반 옵티마이저를 사용할 때만 사용될 수 있는 조인 방식이며
'=' 비교를 통한 조인에서만 사용될 수 있다
주로 많은 양의 데이터를 조인해야 하는 경우에 주로 사용된다
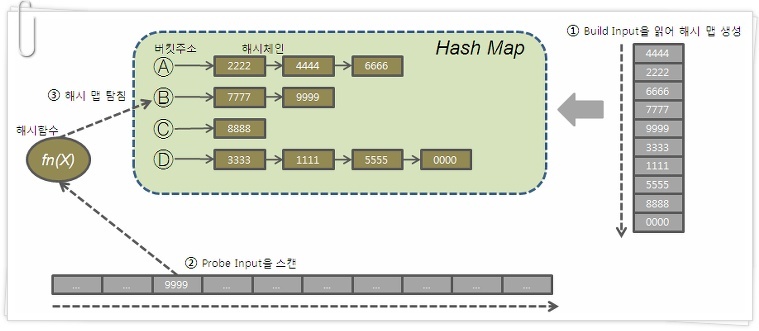
첫 번째로 둘 중 작은 집합(Build Input)을 읽어 Hash Area에 해시 테이블을 생성한다
(해시 함수에서 리턴 받은 버킷 주소로 찾아가 해시 체인에 엔트리를 연결)
두 번째로 반대쪽 큰 집합(Probe Input)을 읽어 해시 테이블을 탐색하면서 JOIN 한다
세 번째로 해시 함수에서 리턴 받은 버킷 주소로 찾아가 해시 체인을 스캔하면서 데이터를 찾는다